
Website pagination is when pages—usually with similar content—are organized into a sequential series.
Pagination can use elements like numbered buttons or links. Which helps users move through a content archive.
The most common examples of pagination are found within blog archive pages. And ecommerce category pages.
Here’s an example of pagination from our blog:

We use numbered buttons. Users can click these buttons to browse our collection of articles.
And here’s pagination from ecommerce shop The Shoe Company. They use numbered links and arrows.

You can also find pagination on things like product reviews, blog comments, and forum pages.
When done right, pagination can be good for SEO.
But it also has its risks.
Let’s explore how a pagination SEO strategy can help you. And how it can be counterproductive when implemented incorrectly.
Improves User Experience
Pagination improves the user experience because it lets users move through large amounts of content more efficiently.
Plus, numbered pages tell users where they are in your content. And how much content they have to navigate.
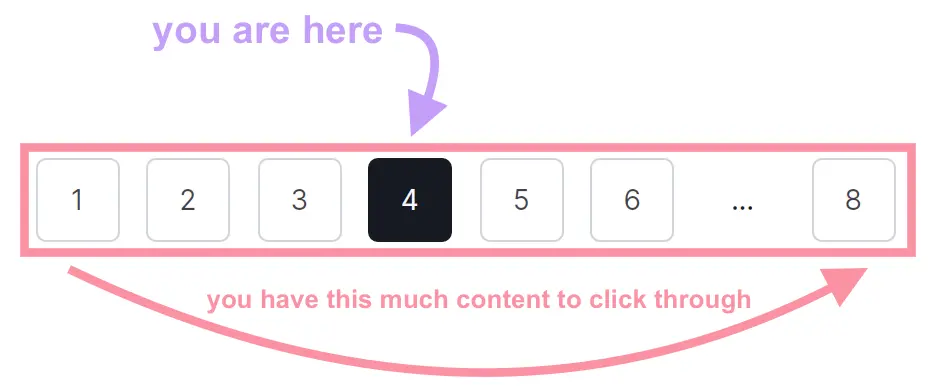
For example, say someone is buying shoes on a website.
According to the pagination, they have 99 pages to click through.
Knowing this, the user might decide to filter the selection by size. So they don’t have as many pages of shoes to look at.
Faster Page Load
Your pages may load faster if you only display a partial amount of content.
And it’s essential your pages load fast.
Why?
Because page speed is a confirmed ranking factor for Google.
And pages that load fast prevent high bounce rates—the percentage of people who leave your site after viewing only one page.

By improving your page speed with pagination, you can increase your chance of ranking higher in the search results. And keep visitors clicking around your site.
Internal Links
Pagination offers internal linking opportunities.
Internal links—links on your website that point to different pages on your website—help search engines understand your site’s structure.
And pass authority to other pages. Which can improve your rankings.
Duplicate Content
Site owners who set up pagination incorrectly risk duplicate content. Which can hurt your SEO efforts.
Duplicate content occurs when your site has the same content in multiple places.
For example, say your ecommerce shop has a “View all” button along with paginated archives.

If pagination hasn’t been set up correctly (which we’ll discuss later), you risk duplicate content.
Why?
Because the content on each of the paginated pages is the same as the content on the “View all” page.
Then, when search engines crawl your site, they may see the duplicate content.
Reduced User Engagement
One purpose of pagination is to help users navigate your site. But if pagination isn’t set up correctly, users might actually be less likely to click through each page.
Imagine landing on a website with hundreds of pages to click through.
Instead of clicking through each page, you might feel overwhelmed and leave.
To solve this, set up pagination in a way that’s meaningful to users.
For example, break up your content into categories. And then paginate those category pages.
1. Self-Canonicalize Each Page
A self-referencing canonical tag on each paginated page can prevent duplicate content.
But first, what is a canonical tag?
A canonical tag is a way of showing search engines which page is the preferred page on your site. It’s typically found in the <head> section of a webpage and looks like this:
<link rel="canonical" href="https://example.com/preferred-url-here/"/>
A self-referencing canonical tag is when the canonical tag in a webpage’s HTML code points to the same page it’s on.
When you use a self-referencing canonical tag on paginated pages, you’re telling search engines that the content on each paginated page is the “primary” version of the page.
Even if there are similar pages elsewhere on your site (like a “View all” page).
Here’s another example: If you have an ecommerce shop, you likely have a paginated list of products.
However, users can also sort those products by price.
This sorting results in pages of similar content to your paginated archives.
Without a canonical tag, search engines would see these similar pages. And they might not understand which page is the primary page (and which one to index in the search results).
The solution? Add a self-referencing canonical tag in the <head> of each paginated page.
Here’s how that could look:
- Page 1: <link rel=”canonical” href=”https://example.com/shop/”>
- Page 2: <link rel=”canonical” href=”https://example.com/shop/?page=2″>
- Page 3: <link rel=”canonical” href=”https://example.com/shop/?page=3″>
And so on.

After adding self-referencing canonical tags, check them to ensure they’re set up correctly. You can check your canonical tags with Semrush’s Site Audit.
To start a new Site Audit, click “+ Create project.”

Next, follow our configuration guide to set up your site’s audit for your needs. Once Semrush has finished the audit (which can take up to 24 hours), you’ll see a page with an overview of your site’s health.

Click on the “Crawled Pages” tab. Add the filters as shown:

This displays all pages with a self-canonical tag. So you can keep track of which pages have them.
2. Use Clear URLs
Clear URLs help users and search engines navigate paginated content.
In the past, SEOs used “rel=prev/next” attribute values to indicate the relationship between paginated pages. It looked like this:

The prev/next values told search engines which page came before each page. And which one came next. However, Google has since retired “rel=prev/next.”
Spring cleaning!
As we evaluated our indexing signals, we decided to retire rel=prev/next.
Studies show that users love single-page content, aim for that when possible, but multi-part is also fine for Google Search. Know and do what’s best for *your* users! #springiscoming pic.twitter.com/hCODPoKgKp— Google Search Central (@googlesearchc) March 21, 2019
So, it’s essential to have clear and unique URLs to help search engines determine the order of your pages. Like this:

These types of URLs help Google understand the relationship between each page. Plus, they make it easy for users to quickly identify where they are on your website. And navigate to other pages within your pagination as needed.
3. Avoid URL Fragment Identifiers
Fragment identifiers are hashes in URLs.
Like this: https://example.com/blog/#page2.

Google ignores fragment identifiers. And may not follow links that include fragment identifiers. Meaning your paginated content might not be crawled by Google.
Instead, use query parameters. Query parameters are elements added to the end of a URL. They’re search engine-friendly and will allow search engines to crawl paginated content.
Like this: https://example.com/blog/?page=2.

4. De-Optimize Paginated Pages
De-optimizing paginated pages encourages search engines to display the main page (or root page) in the search results.
Google treats paginated pages as normal pages, according to Google’s John Mueller.
Which means your paginated pages could end up competing against your root page in the search results.
And you likely want to send traffic to the root page. Instead of a miscellaneous page in the middle of your paginated series.
To dissuade search engines from indexing numbered pages, de-optimize the title tag (which often forms the clickable link in the search results). One way to do this is by adding “Page #” to the start of your title tag. Like this:

You can also de-optimize the H1 tag on each paginated page in a similar fashion to the above. The H1 tag is the main title on a webpage:

5. Avoid Noindexing Paginated Pages
A “noindex” tag instructs search engines not to index a page in the search results. It can appear in the <head> section of a webpage. And can look like this:
<meta name="robots" content="noindex">
You might feel tempted to “noindex” paginated pages (to keep them out of the search results).
But doing this can have unintended consequences. And might exclude from search engines pages that bring you traffic.
Instead, follow our tips from above to de-optimize paginated pages and encourage search engines to index the root page instead.
There are three alternatives to pagination:
- Infinite scrolling
- Load more
- View all
Let’s discuss each one:
Infinite Scrolling
Infinite scroll is when content loads automatically as the user scrolls down the page.
It can increase user engagement. As users don’t need to click and wait for content to load.
However, infinite scroll can hurt the user experience.
Why?
Because if users want to get to the end of your page (and access the footer), they may have to scroll for a while. Which could cause them to feel frustrated and leave your site.
And Google might not be able to access all the content behind an infinite scroll depending on how it’s set up, according to Google’s John Mueller. Which can negatively impact your pagination SEO efforts.
Load More
“Load more” buttons let users click a button to load more content. This way, users have more control over when they see new content. Which provides a balance compared to infinite scrolling.

However, “load more” buttons can cause SEO issues.
First, too many pages within a “load more” pagination creates a deep site structure. Which means it takes more clicks for users to reach their desired page. Like this:

For example, if a user wants to access a product on page five, they have to click the “Load more” button four times to get there. Which can hurt the user experience.
This can also have a negative impact on your SEO. Google doesn’t crawl content behind JavaScript “load more” buttons, according to John Mueller. So, search engines can often miss content on any pages that require users to “load more.”
View All
The “view all” option gives users all the content on the page. And eliminates the need for pagination or incremental loading.

A “view all” button can work when you have a manageable amount of content that won’t overwhelm users.
This way, users get a quick view of what you have to offer. And decide how they’d like to navigate your site.
However, if you have thousands of products or pages, a “view all” option might be too much for users.
Not to mention, a large amount of content can slow down your site. Which can hurt your SEO and lower your rankings.
Monitoring and Tracking Pagination
You can track pagination in four different ways depending on your needs:
Site Audit
Use Semrush’s Site Audit to view canonical errors. After configuring your audit, click on the “Issues” tab. Then, search “canonical.”

This displays any errors you have with canonical tags. Like duplicate content (where you may need a canonical tag). Or pages with multiple canonical URLs (you should only have one canonical URL per page).
Tracking these issues helps keep your pagination running smoothly.
Google Search Console
Google Search Console (GSC) shows you if paginated pages rank in the search results. And how much traffic each page gets.

To start, head to “Search results” under the “Performance” tab. (Some accounts may not see “Search results.” In which case, click “Performance.”)

Along the top, click “+ New” and “Page.”

Select “URLs containing” from the drop-down. Then, enter any identifiers your site uses to distinguish paginated pages from other pages. Like this:

Click “Apply.”
This displays a list of your paginated URLs. Pay attention to the number of clicks each page gets and its position.

Ideally, you want the majority of traffic heading to your root pages. And you may need to de-optimize paginated pages that get more traffic than the root page.
Google Analytics
Google Analytics 4 (GA4) can tell you how people behave on your paginated pages.
To start, head to “Engagement” and “Pages and screens.”

In the search bar, enter the identifier for your paginated pages.

This displays information on your pages. Like which pages get the most views and how much time people spend on your paginated pages.
You can use this information to determine the effectiveness of your paginated pages.
For example, compare the average engagement time (the average time your site was in focus in a user’s browser) across different pages.
Look for anomalies. And try to understand why people might spend more—or less—time on certain pages.
This could help you pinpoint paginated pages that aren’t user-friendly.
Server Log Files
Server log files—files that record server activities—are an advanced way to track how search engines crawl and interact with site content.
They can alert you to patterns and potential issues. Like if your paginated pages are taking up too much of your crawl budget—the amount of time and resources a search engine will allocate to crawling your site.
This might happen if your paginated pages have excessive duplicate content. Which means you may need to implement canonical tags.
With Semrush’s Log File Analyzer, you can upload your site’s log files to identify the most crawled pages on a website. And discover opportunities to manage bot activity and optimize the crawl budget.

Optimize Your Paginated Archives
Reviewing paginated content can improve your site’s user experience.
And by adding canonical tags to the right pages, you can help search engines understand your content.
Semrush’s Site Audit tool helps you manage and track your canonical tags. So you don’t need to worry about duplicate content issues.
Want to review your canonical tags for your pagination SEO strategy?
Try Semrush’s Site Audit—for free—today.





